postgresql 被称为「最现代的关系型数据库」,其支持倒排索引,可用于全文检索。在数据量不大的情况下,即使不使用 elasticsearch 也能达到不错的性能。
postgresql 默认的分词器以空格分词,不支持中文。为使其支持中文,可参考以下两篇文章的做法,安装和应用 zhparser:
https://www.cnblogs.com/zhenbianshu/p/7795247.html
https://www.cnblogs.com/Amos-Turing/p/14174614.html
其中添加分词配置的代码为:
1
2
|
CREATE TEXT SEARCH CONFIGURATION parser_name (PARSER = zhparser);
ALTER TEXT SEARCH CONFIGURATION parser_name ADD MAPPING FOR n,v,a,i,e,l,j WITH simple;
|
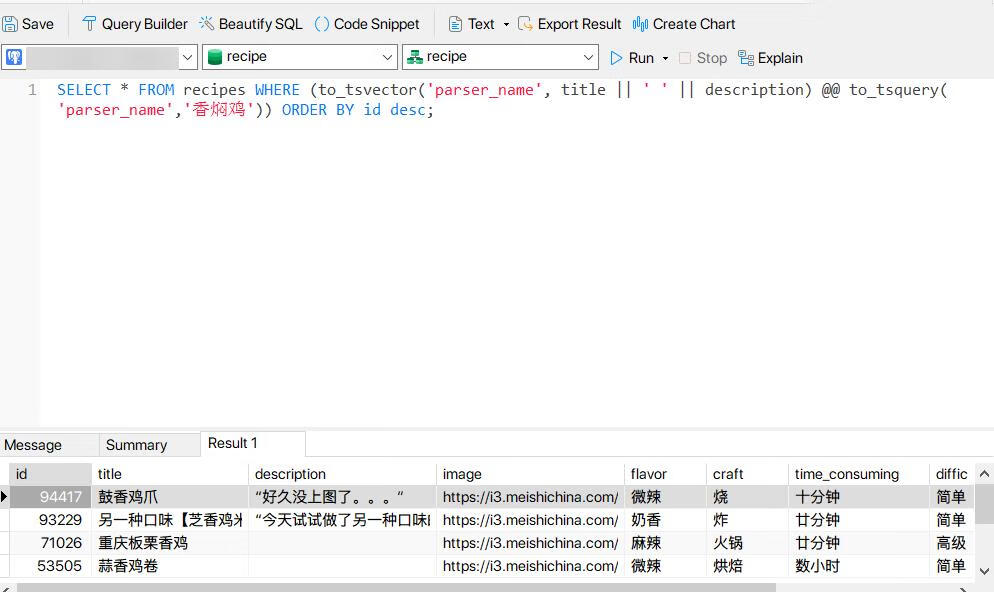
我在数据库 recipe 中建立了名为 recipe 的 schema,使用 recipe 账户登录。在title || ' ' || description字段上建立索引,使用 Navicat 查询效果如下图:
在 Java 中的 SelectProvider 中定义的方法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public String findAllRecipes(RecipeFilter recipeFilter) {
return new SQL(){{
SELECT("*");
FROM("recipes");
if (!recipeFilter.getFlavor().isEmpty()) {
WHERE("flavor=#{flavor}");
}
if (!recipeFilter.getCraft().isEmpty()) {
WHERE("craft=#{craft}");
}
if (!recipeFilter.getTimeConsuming().isEmpty()) {
WHERE("time_consuming=#{timeConsuming}");
}
if (!recipeFilter.getDifficulty().isEmpty()) {
WHERE("difficulty=#{difficulty}");
}
if(!recipeFilter.getSearch().isEmpty()){
WHERE("to_tsvector('parser_name', title || ' ' || description) " +
" @@ to_tsquery('parser_name',#{search})");
}
ORDER_BY("id desc");
OFFSET("#{offset}");
LIMIT("#{limit}");
}}.toString();
}
|
遇到报错:
1
2
|
org.springframework.jdbc.BadSqlGrammarException:
### Error querying database. Cause: org.postgresql.util.PSQLException: ERROR: text search configuration "parser_name" does not exist
|
parser_name是已经定义的 parser,在 Navicat 中查询没有问题,但在程序中查询却出现问题了。
这是由于分词器是建立在public的 schema 上的:
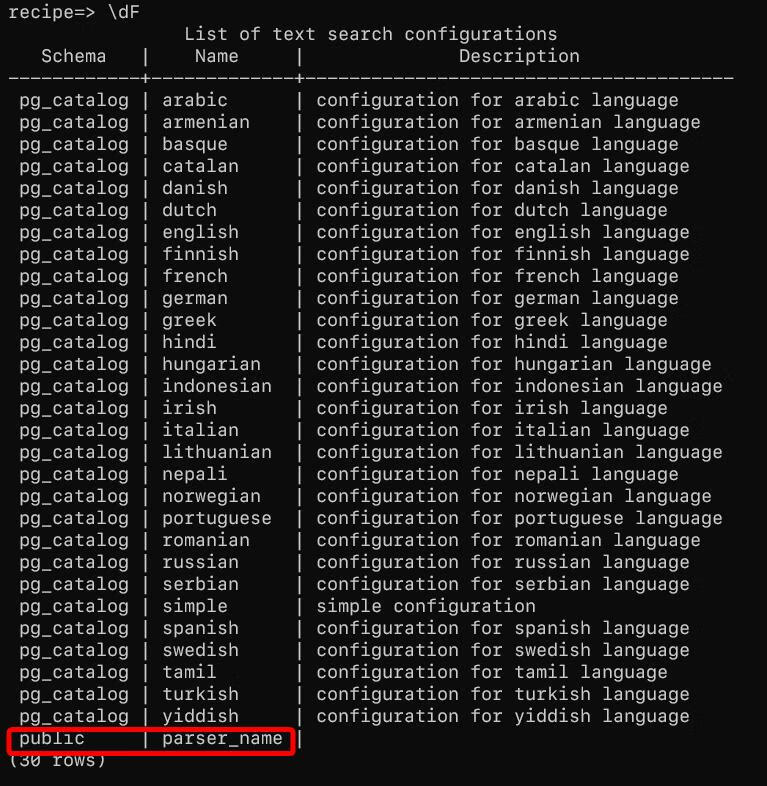
解决方法:在 parser 名字前添加public:
1
2
|
WHERE("to_tsvector('parser_name', title || ' ' || description) " +
" @@ to_tsquery('parser_name',#{search})");
|
改为:
1
2
|
WHERE("to_tsvector('public.parser_name', title || ' ' || description) " +
" @@ to_tsquery('public.parser_name',#{search})");
|
这样就成功在 MyBatis 中查询了。
详细分析有待后续补充。
