正文
最近接到一个需求是写爬虫去获取一个医疗相关的网站上的文章。
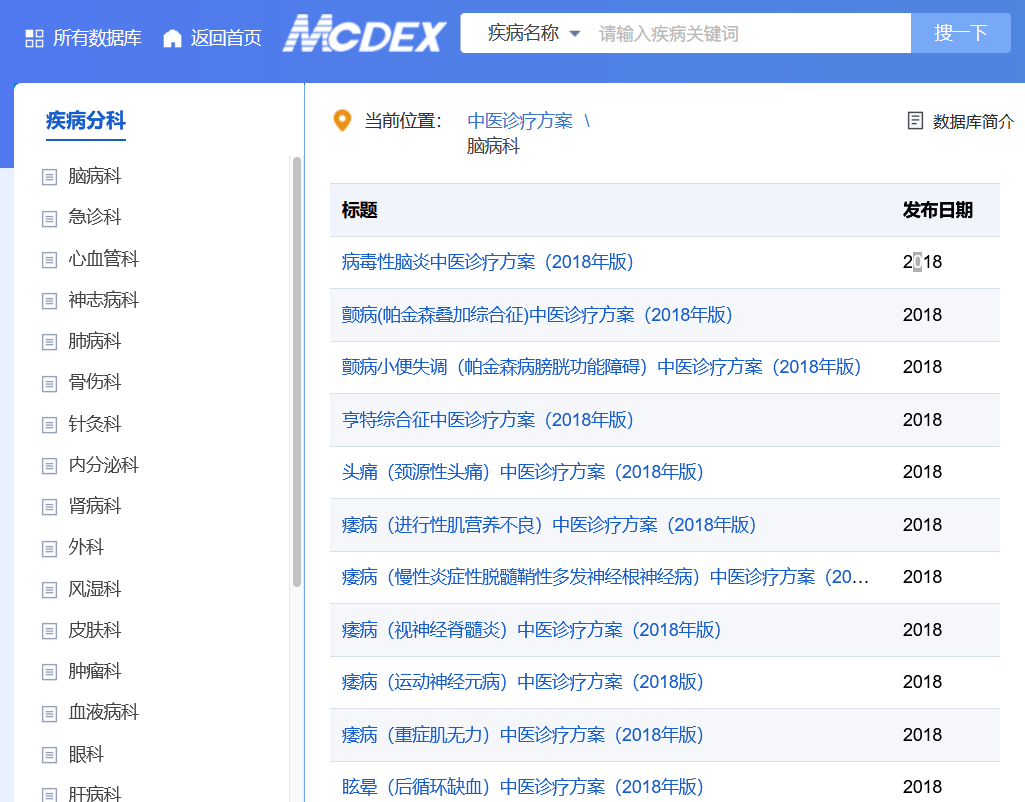

结构首先是一个疾病分科,然后每个分科下有一些文章列表。文章列表点进去是具体的文章。我们的目标是爬取每个分科下的所有文章。
首先用浏览器控制台抓包,发现所有的请求都是基于 ajax 的。我们在下面的表示中将展示请求 URL、请求 Body 和响应 Body,分别用两个换行符隔开。
其中获取疾病分科列表的请求很简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
POST http://222.174.23.82:10000/sdt/getClass
(请求不带body)
{
"code": 200,
"msg": "操作成功",
"data": {
"list": [
{
"sdtTitle": null,
"documentdate": null,
"diseaseclass": "脑病科",
"diseaseIdCode": "23d44a2191c296bda19c2f160848652c",
"sdtContent": null,
"sdtLinkCg": null,
"sdtLinkCmp": null,
"sdtLinkCri": null,
"sdtLinkMcp": null,
"isLeaf": 1,
"sdtIdCode": null
},
...
{
"sdtTitle": null,
"documentdate": null,
"diseaseclass": "传染病科",
"diseaseIdCode": "699935705000153db51d5ccf3f69ec12",
"sdtContent": null,
"sdtLinkCg": null,
"sdtLinkCmp": null,
"sdtLinkCri": null,
"sdtLinkMcp": null,
"isLeaf": 1,
"sdtIdCode": null
}
]
}
}
|
接下来理应是用这个 diseaseIdCode 作为参数去获取每个分科下的文章列表。让我们继续抓包:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
POST http://222.174.23.82:10000/sdt/getClassTitles
{
"classIdCode": "T6bGLx+Q/a3g9X8uJSMAEswFPA5PhVzTNJYGjPM8bFdtaGmlV+n0yMo/UC8kYssAH68ZgpTJ4kHz0oQtG0n0979BoxHric5DDzZzklrsW8ob549s3V1axR+ChEBmIkSSTU67ubBnc9Cu4Wh6uYQmBn6VZsFHxy6zp0owcdTD1jQ="
}
{
"code": 200,
"msg": "操作成功",
"data": {
"total": 29,
"data": [
{
"sdtTitle": "病毒性脑炎中医诊疗方案(2018 年版)",
"documentdate": 2018,
"diseaseclass": null,
"diseaseIdCode": "23d44a2191c296bda19c2f160848652c",
"sdtContent": null,
"sdtLinkCg": null,
"sdtLinkCmp": null,
"sdtLinkCri": null,
"sdtLinkMcp": null,
"isLeaf": 1,
"sdtIdCode": "da60d0d0108b4d5b81f831d8b990a689"
},
...
{
"sdtTitle": "痿病(多发性硬化)中医诊疗方案(2017 年版)",
"documentdate": 2017,
"diseaseclass": null,
"diseaseIdCode": "23d44a2191c296bda19c2f160848652c",
"sdtContent": null,
"sdtLinkCg": null,
"sdtLinkCmp": null,
"sdtLinkCri": null,
"sdtLinkMcp": null,
"isLeaf": 1,
"sdtIdCode": "0c08fac8a06e6dae8779137d75a7c37f"
}
],
"pageNum": 1,
"pageSize": 15
}
}
|
容易发现分科的 diseaseIdCode 实际上对应的是这一步请求中的 classIdCode。但这里出现的问题是 classIdCode 被加密了,并且不是简单的 base64。我们查看相关请求的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
var classIdCode = "23d44a2191c296bda19c2f160848652c";
// ...
function getClassTitles(pageNum) {
$("body").mask("数据查询中,请稍后...");
var params = { classIdCode: classIdCode, pageNum: pageNum };
$.ajax({
type: "post",
url: "/sdt/getClassTitles",
data: JSON.stringify(params),
contentType: "application/json",
dataType: "json",
success: function (result) {
if (result.code === 200) {
var data = result.data;
list_content(data, getClassTitles);
}
},
});
}
|
网站使用了 jQuery,此处也只是调用了一个 jQuery 的 ajax 请求函数,请求 body 也只是做了一个简单的 JSON Stringify。当前我们没有发现可见的加密代码,推测是网站将加密的逻辑直接注入到了 ajax 函数中。下面我们通过在浏览器控制台直接调用$.ajax 函数来验证这一点。
在浏览器控制台执行:
1
2
3
4
5
6
7
|
$.ajax({
type: "post",
url: "/test",
data: '{"a":"b"}',
contentType: "application/json",
dataType: "json",
});
|
查看网络选项卡抓到的包:
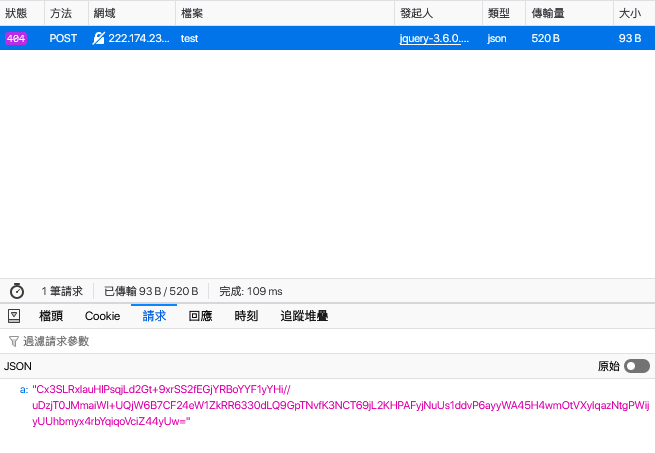
可以看到传入的 b 参数被自动加密了。于是可以验证我们上面的猜想。
正常的爬虫开发逻辑到这一步就该去找加密的代码来逆向了,但这里我们可以换个思路。我们既然已经可以在浏览器控制台中调用网站提供的 ajax 函数,并且可以自动加密请求了。那么我们可不可以直接用 JavaScript 开发爬虫,然后直接在浏览器控制台中运行,需要请求网络时直接调用这个 ajax 函数就行了?
这样也不存在跨域问题,因为我们是在这个网站对应的 JS 运行时中执行爬虫代码,Origin 自动就是这个网站的域名。
获取数据这一点是完全没问题,不过还需要考虑的另一个问题是如何存储爬取的数据。我们希望数据能够马上存储,也就是爬下来一条数据马上存到我们的本地文件中。
要解决这个问题可以在本地起一个 HTTP Server,爬虫爬下来一条数据直接把数据发给我们本地的 HTTP Server,Server 把传过来的数据写到磁盘里就可以了。由于本地的 Server 运行在 127.0.0.1 上,所以我们只需要在 Server 上加一个允许跨域请求就没问题了。
本地的 HTTP Server 使用 Go 开发,代码也是很简单,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
package main
import (
"github.com/rs/cors"
"io"
"net/http"
"os"
"sync"
)
func main() {
mux := http.NewServeMux()
mutex := sync.Mutex{}
mux.HandleFunc("/save", func(w http.ResponseWriter, r *http.Request) {
mutex.Lock()
defer mutex.Unlock()
f, err := os.OpenFile("data.jsonl", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
panic(err)
}
defer f.Close()
v, err := io.ReadAll(r.Body)
if err != nil {
panic(err)
}
_, err = f.Write(v)
if err != nil {
panic(err)
}
})
handler := cors.Default().Handler(mux)
http.ListenAndServe(":3333", handler)
}
|
基本逻辑就是在/save路径上注册路由,然后把 POST Body 追加到本地的 data.jsonl 文件中。这里文件格式是 JSONL(JSON Lines)而不是 JSON,代表每行一个有效的 JSON。
爬虫代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
(() => {
let sleep = (ms) => {
return new Promise(resolve => setTimeout(resolve, ms))
}
let ajax = (url, obj) => {
return new Promise((resolve, reject) => {
$.ajax({
url,
type: "POST",
data: JSON.stringify(obj),
contentType: 'application/json',
dataType: 'json',
success: function (result) {
if (result.code === 200) {
resolve(result.data)
return
}
console.error(result.code)
reject(result.data)
},
error: (err) => {
reject(err)
}
})
})
}
let lastCat = '肛肠科'
let lastArticle = '鹳口疽(骶尾部藏毛窦)中医诊疗方案(2018 年版)'
let main = async () => {
console.log('Getting cat list...')
let catList = await ajax('http://222.174.23.82:10000/sdt/getClass', {})
let catSkip = true
let articleSkip = true
for (let cat of catList.list) {
if (cat.diseaseclass === lastCat) {
catSkip = false
}
if (catSkip) {
continue
}
console.log('Getting ' + cat.diseaseclass)
let currentPage = 1
let articleList = []
let articleListObj = await ajax('http://222.174.23.82:10000/sdt/getClassTitles', {
classIdCode: cat.diseaseIdCode,
pageNum: currentPage,
})
articleList.push(...articleListObj.data)
currentPage++
let totalPage = Math.ceil(articleListObj.total * 1.0 / articleListObj.pageSize)
while (currentPage <= totalPage) {
articleListObj = await ajax('http://222.174.23.82:10000/sdt/getClassTitles', {
classIdCode: cat.diseaseIdCode,
pageNum: currentPage,
})
articleList.push(...articleListObj.data)
currentPage++
}
console.log('Count ' + articleList.length + ' articles')
for (let articleMeta of articleList) {
if (articleMeta.sdtTitle === lastArticle) {
articleSkip = false
continue
}
if (articleSkip) {
continue
}
console.log('Getting article ' + articleMeta.sdtTitle)
let article = await ajax('http://222.174.23.82:10000/sdt/getContent', {
sdtIdCode: articleMeta.sdtIdCode
})
await fetch('http://127.0.0.1:3333/save', {
method: 'post',
body: JSON.stringify({
cat: cat.diseaseclass,
article
}) + '\n'
})
await sleep(2000)
}
}
}
main()
})()
|
需要关注的几个点是:
- 使用 Promise 包装网站提供的$.ajax 函数,这样方便我们使用 async await 的风格调用。
- 由于爬取过程可能中断,于是设置了一个类似断点续传的机制,手动设置我们最新获取到的分类和文章,之前的就跳过。
- getClassTitles 接口获取文章目录时有分页,所以要处理一下分页逻辑。
- 请求文章正文内容的接口同样有加密,于是我们用一样的方法。
- 我们请求被爬取网站用的是 ajax,而请求本地的 HTTP Server 用的是 fetch。因为 ajax 接口自带了加密,而我们将数据发给本地 Server 进行存储时希望是明文的数据。于是这里就直接用了 ES6 标准自带的 fetch 函数来发送数据。
- 测试发现访问太频繁会跳出验证码,于是我们加一个 sleep。
爬取结果展示:

讨论
这里我们是把所有爬虫代码都放在浏览器中执行。如果爬虫的代码比较复杂,我们还是希望用 Go 之类的静态语言开发。这时我们可以考虑把只把浏览器中运行的部分作为一个发送请求和拿到回应的 Agent。比如可以在浏览器中和本地 HTTP Server 建立一个 WebSocket 连接,从连接中获取需要请求的网址和 Body,调用$.ajax 进行请求,将响应通过 WebSocket 发送回去。这样我们可以把爬虫的主代码在本地运行,遇到需要网络请求时就用 WebSocket 把请求发送给浏览器中注入的代码并拿到响应,来进行我们后续的处理。
