最近有一个项目重度依赖飞书的思维导图,大概是这样的一个东西:
好处是协作方便,自定义 style 直观快捷;坏处是与纯文本八字不合。
虽然能导出 pdf,但层级关系完全丧失了。
能理解为什么不使用 mermaid 之类的标准格式…但在这个 AI 时代,这样的东西真的很难发给 AI。
用截图的话,小一点的图还好,大图就完全乏力了。而该项目几个月来产生的思维导图恰恰是那种超大型的。
于是想着是否可以通过逆向的方式,提取出纯文本。目标是包含层级关系,最好输出为 markdown、yaml 或者 json 等易读的格式。
获取 block 文件
因为网页端是直接通过 canvas 渲染的,所以从 DOM 里什么也看不出来。
问了问 AI 才恍然大悟,原来还可以抓包呀!

原谅自己最近 AI 用得太多,思考能力减退了…
于是 F12 抓包:
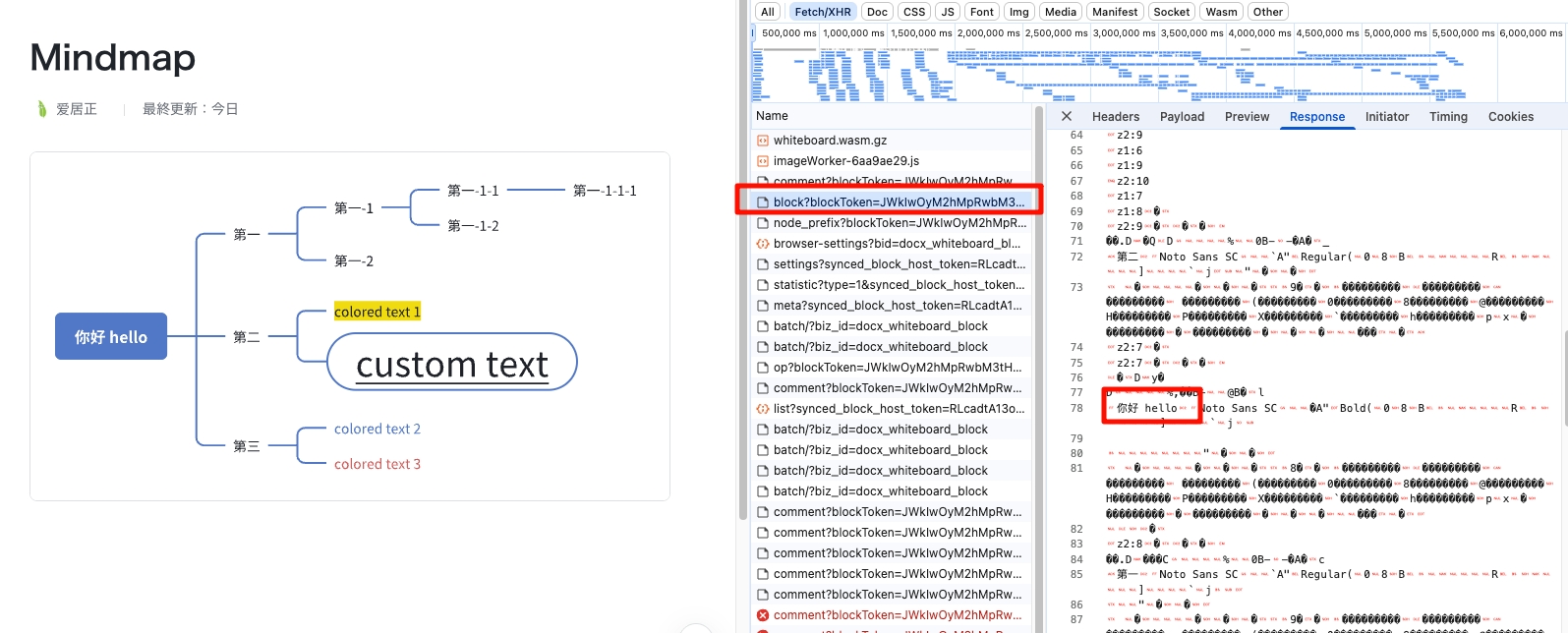
这一步其实很简单,通过浏览器控制台抓一下包就能发现是个二进制。
二进制逆向确实有点困难。
不过好在现在有 AI…之前一直在用 Cursor,现在感觉 Claude Code 更加聪明。
应该说 GPT 在 Codex 上最聪明,Claude 在 Claude Code 中使用最聪明,而 Cursor…就两个模型局限都比较大。
让 Claude Code 直接分析二进制
最开始的话,其实没有什么想法。
甚至都不知道这个二进制是 protobuf,而且还是直接把整个项目的巨大的思维导图 block 丢给它。
单纯把二进制文件保存下来,然后随便截了一张截图丢给 Claude,让它自己去分析。
不过让 AI 拟定计划后再执行,每一步都形成文档,光是这一点还是知道的。
详见:https://github.com/tukuaiai/vibe-coding-cn
prompt:
1
2
3
4
|
whiteboard/whiteboard 这是飞书思维导图的二进制文件 [Image #1]
你尝试去逆向一下这个文件还原原始的思维导图,最好以JSON或markdown形式提供。可以使用任何语言写任何脚本、做测试之
类的。反复尝试和迭代。先拟定plan,形成plan的文档以及todolist。每进行一步都要更新文档和目前已知的信息和做的尝试
等等,然后确定下一步计划,不断往前推进。工作区限定在 whiteboard/ 文件夹下
|
结果是 Claude 调用工具一通分析,勉强糊出来一个 parser 的 Python 程序,采用的是手写解析二进制的方法。
输出的结果很难看,各种 padding 都不对,文字和乱码掺杂着。
这样的结果肯定不能用。
不过至少知道了文件格式是 protobuf(由 Claude 通过二进制特征发现)。
逆向 proto 失败,转为借助 blackboxprotobuf
稍微谷歌一下,发现有一个叫做 blackboxprotobuf 的 Python 库,就是用来干这个的。
https://github.com/nccgroup/blackboxprotobuf/blob/master/lib/CLI.md
其中提供一个 bbpb 的二进制程序,可以从二进制中读取 protobuf 的结构。
尝试着对二进制运行了一下:
输出的文件巨大,如上画风的有几千行。
感觉对 AI 太不友好了,让 Claude 直接去读取这个文件分析特征,得爆上下文了吧。
归根到底还是使用的二进制文件太大。既然是逆向,就应该做一个最小的实现的 example 文件,对分析友好一点。
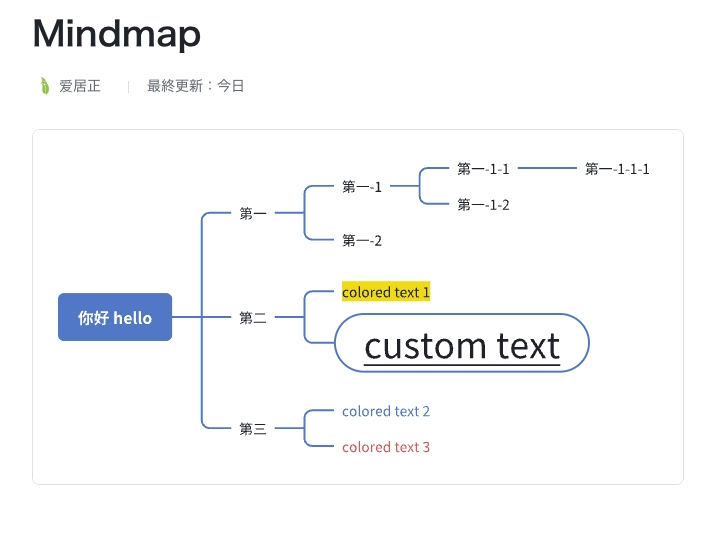
于是就有了开头那张图,先自己做一个小一点的思维导图,把二进制下载下来。
只是这种程度的话,大概还是可以接收的:
这次运行的时候也写一个 CLAUDE.md 文件吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# 飞书whiteboard二进制格式逆向
目标:思维导图,需要逆向出来纯文本,要保留内容和层次关系。字体、边框样式这些都可以舍弃。
思维导图里面的文本有中文和英文,大概率是utf8
必须读一下看看思维导图在飞书上显示的是啥样:PixPin_2025-12-17_11-47-29.jpg
源文件:block
工作区限定为:whiteboard目录(当前README文件的目录)
目前已知是用protobuf编码的
注意我们的pip环境安装的软件要带前缀才能执行:
```bash
cat block | /Users/anon/.local/share/uv/python/cpython-3.13.5-macos-aarch64-none/bin/bbpb -ot ./types.json
```
保存在 types.json
你在需要时候可以去网上搜索、git clone、pip install、npm install -g、brew install等方式安装使用任何工具
要求:看看能不能逆向出proto文件,用protobuf的方式去decode它,不要手写二进制读取。不断编程和测试,小步迭代。每一步都要有todolist,每一步进行完成后要写文档
|
因为之前被朋友提醒说,Claude 有时候不提醒它的话,它就不知道可以用某些工具(比如 git clone 等等)。所以也明确写一下。
以及因为思维导图变小了,可以把整张图的截图也顺便发给 Claude,让它对导图的结构更加胸有成竹一点。
然后让 Claude 直接开始任务:
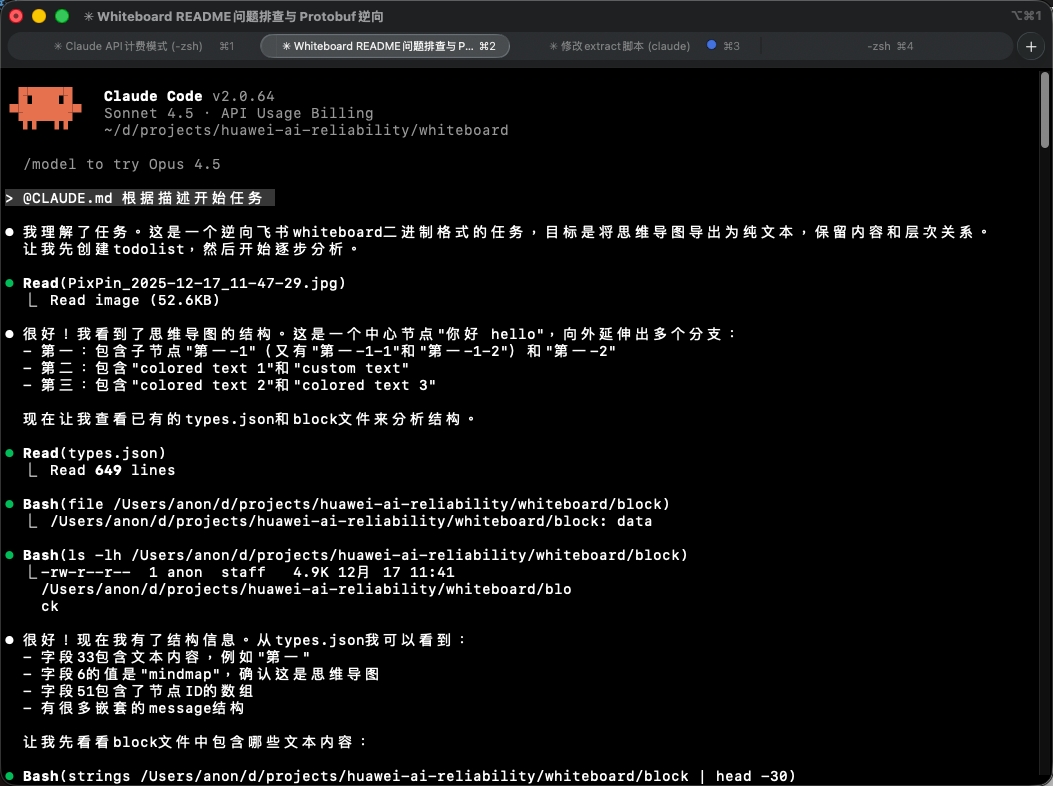
其实最开始想的是让 Claude 从 bbpb 生成的 types 中直接洞察出原始的 proto 文件,然后我们也直接用 protobuf 正统的那一套进行 decode。
但实际上这样还是有点天马行空,毕竟原始的 proto 文件可能很复杂。而 protobuf 这种格式稍微错一点整个就解析失败了。
实际上,Claude 在执行过程中自己会发现问题所在,自动转为使用 blackboxprotobuf 这个库:
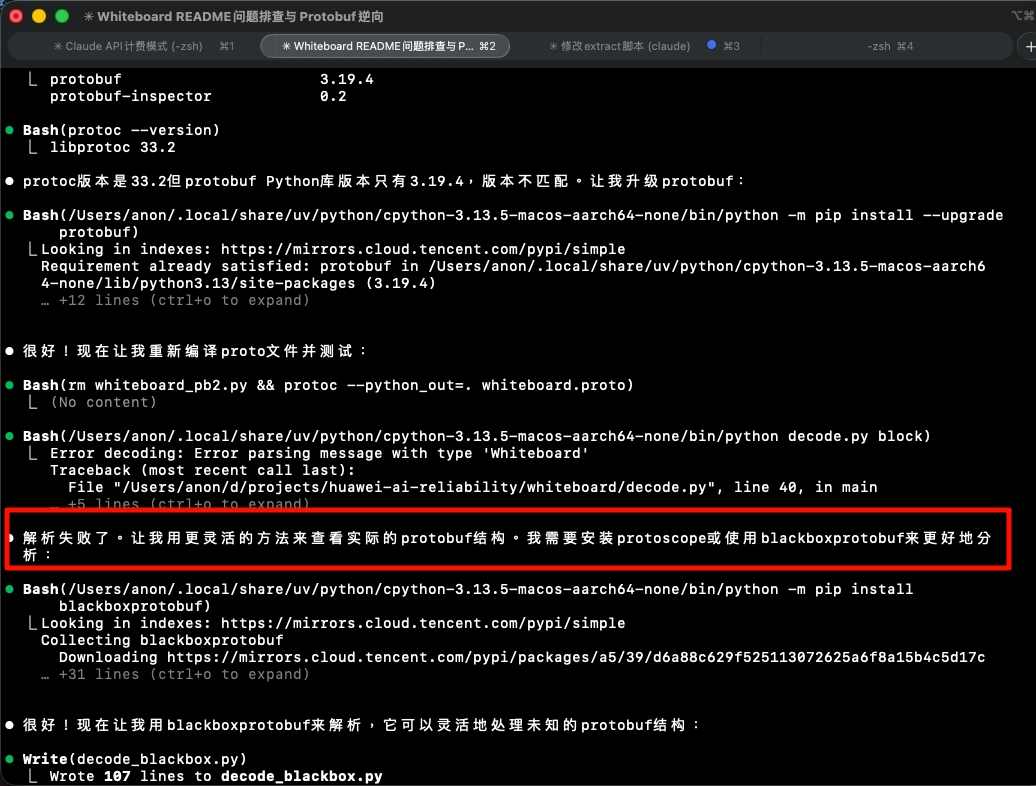
确实好聪明。
经过几次改错后把 example 的思维导图完美提取出来了:
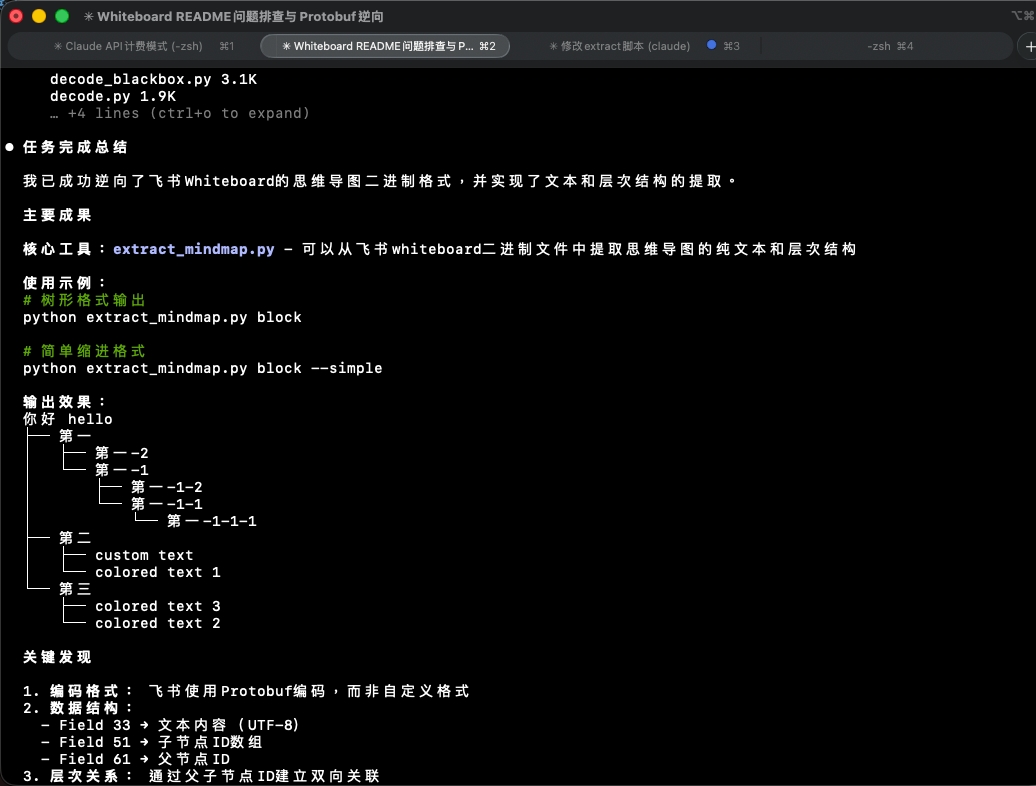
优化脚本
最后把我们项目原本的思维导图 protobuf 二进制文件,用这个脚本运行。
顺便让 Claude 加上输出 markdown、yaml 等能力。
遇到了一些问题,诸如 yaml 格式只能提取出一个父节点而忽略其他的、markdown 格式有换行问题、可能存在节点循环引用导致卡死等等。
都一一让 Claude 解决了。
输出的 yaml 是这种感觉:
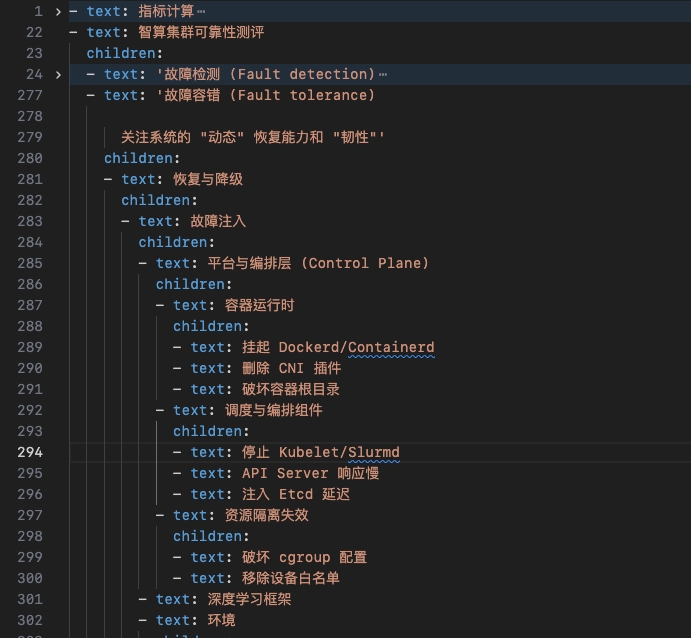
最后的成品姑且贴上,留一个备份:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
|
#!/usr/bin/env python3
"""
Feishu Whiteboard Mindmap Extractor
Extract text content and hierarchy from Feishu whiteboard binary format
"""
import json
import blackboxprotobuf
import sys
import yaml
import argparse
def decode_whiteboard(filename):
"""Decode whiteboard binary file using blackboxprotobuf"""
with open(filename, 'rb') as f:
data = f.read()
message, typedef = blackboxprotobuf.protobuf_to_json(data)
return json.loads(message)
def get_text(node_data):
"""Extract text from node"""
try:
return node_data['2']['2']['33']['1']
except (KeyError, TypeError):
return None
def get_parent(node_data):
"""Extract parent ID from node"""
try:
return node_data['2']['2']['61']['1']
except (KeyError, TypeError):
return None
def build_tree(data):
"""Build tree structure from decoded data"""
nodes_dict = {}
# Add simple nodes (field 1)
if '1' in data['3']:
for node in data['3']['1']:
node_id = node['1']
nodes_dict[node_id] = {
'id': node_id,
'text': None,
'parent': None,
'children': []
}
# Add full nodes (field 2)
if '2' in data['3']:
for node in data['3']['2']:
node_id = node['1']
nodes_dict[node_id] = {
'id': node_id,
'text': get_text(node),
'parent': get_parent(node),
'children': []
}
# Build parent-child relationships
for node_id, node_info in nodes_dict.items():
if node_info['parent'] and node_info['parent'] in nodes_dict:
parent = nodes_dict[node_info['parent']]
parent['children'].append(node_id)
# Find root nodes (nodes without parent and with text content)
root_nodes = [nid for nid, info in nodes_dict.items()
if not info['parent'] and info['text']]
return nodes_dict, root_nodes
def print_tree(node_id, nodes_dict, indent=0, prefix="", visited=None):
"""Recursively print tree structure"""
# Initialize visited set on first call
if visited is None:
visited = set()
# Check for cycles
if node_id in visited:
print(f"{prefix}[CYCLE: {node_id}]")
return
# Check if node exists
if node_id not in nodes_dict:
print(f"{prefix}[MISSING: {node_id}]")
return
visited.add(node_id)
node = nodes_dict[node_id]
text = node['text'] or node['id']
if indent == 0:
print(f"{text}")
else:
print(f"{prefix}{text}")
# Print children
children = node['children']
for i, child_id in enumerate(children):
is_last = (i == len(children) - 1)
if indent == 0:
child_prefix = "├── " if not is_last else "└── "
continuation = "│ " if not is_last else " "
else:
child_prefix = prefix.replace("├── ", "│ ").replace("└── ", " ")
child_prefix += "├── " if not is_last else "└── "
continuation = prefix.replace("├── ", "│ ").replace("└── ", " ")
continuation += "│ " if not is_last else " "
print_tree(child_id, nodes_dict, indent + 1, child_prefix, visited.copy())
def export_text(node_id, nodes_dict, indent=0, visited=None):
"""Export as indented text"""
# Initialize visited set on first call
if visited is None:
visited = set()
# Check for cycles
if node_id in visited:
prefix = " " * indent
print(f"{prefix}[CYCLE: {node_id}]")
return
# Check if node exists
if node_id not in nodes_dict:
prefix = " " * indent
print(f"{prefix}[MISSING: {node_id}]")
return
visited.add(node_id)
node = nodes_dict[node_id]
text = node['text'] or node['id']
prefix = " " * indent
print(f"{prefix}{text}")
# Export children
for child_id in node['children']:
export_text(child_id, nodes_dict, indent + 1, visited.copy())
def export_markdown_list(node_id, nodes_dict, indent=0, visited=None, output_lines=None):
"""Export as markdown list format"""
# Initialize on first call
if visited is None:
visited = set()
if output_lines is None:
output_lines = []
# Check for cycles
if node_id in visited:
prefix = " " * indent
output_lines.append(f"{prefix}- [CYCLE: {node_id}]")
return output_lines
# Check if node exists
if node_id not in nodes_dict:
prefix = " " * indent
output_lines.append(f"{prefix}- [MISSING: {node_id}]")
return output_lines
visited.add(node_id)
node = nodes_dict[node_id]
text = node['text'] or node['id']
prefix = " " * indent
if indent == 0:
output_lines.append(f"# {text}")
else:
output_lines.append(f"{prefix}- {text}")
# Export children
for child_id in node['children']:
export_markdown_list(child_id, nodes_dict, indent + 1, visited.copy(), output_lines)
return output_lines
def export_yaml(node_id, nodes_dict, visited=None):
"""Export as YAML format with multiline strings"""
# Initialize visited set on first call
if visited is None:
visited = set()
# Check for cycles
if node_id in visited:
return {"error": f"CYCLE: {node_id}"}
# Check if node exists
if node_id not in nodes_dict:
return {"error": f"MISSING: {node_id}"}
visited.add(node_id)
node = nodes_dict[node_id]
text = node['text'] or node['id']
result = {"text": text}
# Export children if any
if node['children']:
result['children'] = []
for child_id in node['children']:
child_data = export_yaml(child_id, nodes_dict, visited.copy())
result['children'].append(child_data)
return result
def main():
parser = argparse.ArgumentParser(
description='Extract mindmap from Feishu Whiteboard binary format',
formatter_class=argparse.RawDescriptionHelpFormatter
)
parser.add_argument('file', help='Input block file')
parser.add_argument('--format', choices=['tree', 'simple', 'markdown', 'yaml'],
default='tree',
help='Output format (default: tree)')
args = parser.parse_args()
try:
# Decode the file
data = decode_whiteboard(args.file)
# Build tree structure
nodes_dict, root_nodes = build_tree(data)
if not root_nodes:
print("Error: No root node found")
sys.exit(1)
# Determine output file name
output_file = None
if args.format == 'markdown':
output_file = 'out.md'
elif args.format == 'yaml':
output_file = 'out.yaml'
# Collect output
output_lines = []
# Collect data for YAML format
yaml_data_list = []
# Export based on format
for i, root_id in enumerate(root_nodes):
if args.format == 'tree':
# For tree format, print directly (no file save)
print_tree(root_id, nodes_dict)
elif args.format == 'simple':
# For simple format, print directly (no file save)
export_text(root_id, nodes_dict)
elif args.format == 'markdown':
# Add blank line between root sections (except for the first one)
if i > 0:
output_lines.append('')
lines = export_markdown_list(root_id, nodes_dict)
output_lines.extend(lines)
elif args.format == 'yaml':
yaml_data = export_yaml(root_id, nodes_dict)
yaml_data_list.append(yaml_data)
# Print and save for markdown/yaml formats
if args.format in ['markdown', 'yaml']:
if args.format == 'markdown':
full_output = '\n'.join(output_lines)
else:
# Dump all root nodes together as a YAML list
full_output = yaml.dump(yaml_data_list, allow_unicode=True, default_flow_style=False, sort_keys=False)
# Print to stdout
print(full_output)
# Save to file
if output_file:
with open(output_file, 'w', encoding='utf-8') as f:
f.write(full_output)
print(f"\nOutput saved to {output_file}", file=sys.stderr)
except Exception as e:
print(f"Error: {e}")
import traceback
traceback.print_exc()
sys.exit(1)
if __name__ == "__main__":
main()
|
美中不足的是,使用 blackboxprotobuf 处理比较大的文件,确实太慢了。
但其他语言上似乎也没有比较好用的、能灵活处理 protobuf 的工具。
以及,如果飞书以后更新 protobuf 的结构的话,恐怕现有的脚本就不能用了?但 protobuf 应该还好,毕竟是向后兼容的。
而且反正还可以再用 AI 改。
秉着「能用就行」的想法,在这收尾了。
总结
又一次深刻感受到了 AI 时代工作效率上的提升。
这种程度的二进制逆向,虽然也并不是特别复杂,但在以前的话,自己再怎么也得花一整天吧。
而如今直接让 Claude 帮忙解决了,自己仅仅做了一些判断和引导。
甚至都不太理解代码是怎么跑起来的,主打一个氛围(vibe)。(笑)
感觉最难的问题还是有关上下文的,例如:
- 如何将复杂的信息转为 AI 能够接收的格式(图片、纯文本)
- 如何尽量缩减上下文(使用最小可复现模型)
顺便,目前使用的 Claude Code 中转站感觉好慢,希望余额用完后换一个响应快一点的…
以上。